-
대형폐기물 배출 신고을 하고 신고필증을 제공해주는 어플리케이션을 개발하는 프로젝트이다.
배출 신고 과정 중 품목을 선택하는 부분이 있는데 품목 선택을 딥러닝을 이용해서 품목 인식을 하려한다.
현재는 품목들 중 장롱을 인식하는 것을 목표로 하였다.
저번학기에는 장롱이미지와 장롱이 아닌 이미지를 분류하기 위해서 웹크롤링을 통해 이미지들을 수집하였고 그렇게 얻은 train data는 약 250장으로 데이터의 수가 꽤 부족하였다.
그래서 데이터를 확대시켜 클래스마다 20000장으로 구성한 후 CNN 모델을 만들어서 훈련시켰는데 정확도는 약 97%가 나왔지만 테스트 데이터로 평가했을 때는 그다지 높지 않은 결과를 얻었었다.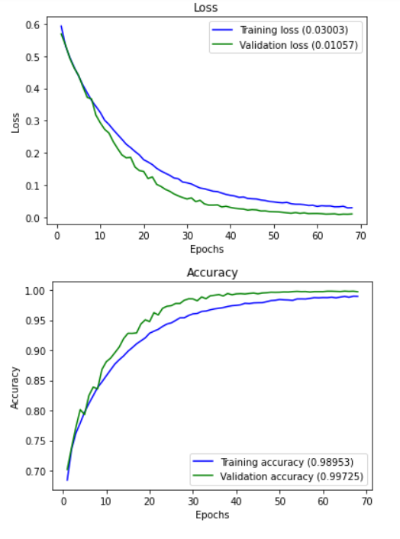
데이터수가 부족한 것이 원인이라고 판단하여 이번학기에는 좀 더 데이터를 확보한 후 모델 학습을 하기로 하였다.
[이미지 데이터셋 구축]
아래는 이미지넷으로 굉장히 많은 이미지들을 대량으로 가지고 있는 사이트이다.ImageNet
Mar 11 2021. ImageNet website update.
www.image-net.org
이미지넷 사이트에 들어가서 검색창에 원하는 이미지를 검색하거나 이미지들이 카테고리별로 분류가 되어있으며 원하는 카테고리를 클릭하여 다운로드 받으면 된다.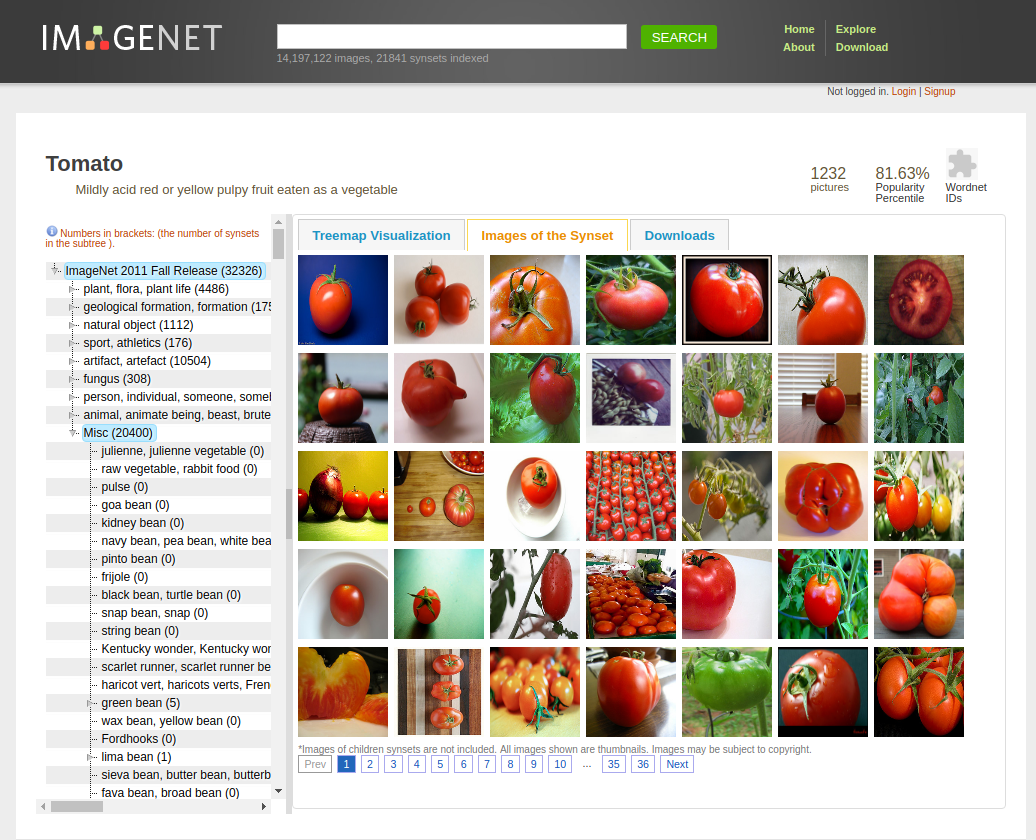
이미지넷 사이트 이미지넷을 통해서 장롱 이미지와 장롱이 아닌 이미지들(에어컨, 책장, 책상 등)의 이미지들을 다운받았는데 각 카테고리마다 약 1000~2000장 정도의 이미지를 얻을 수 있었다.

장롱 이미지 
장롱이 아닌 이미지
이전에 크롤링을 통해 얻은 이미지들까지 포함해서 하나의 폴더에 모은 후 폴더 내에 중복된 이미지가 있는지 확인해보았다.모델 학습을 시킨 후, 학습을 시켰던 이미지와 중복된 이미지로 테스트를 진행할 경우 같은 이미지이므로 100% 일치하는 것으로 인식한다. 이러한 오류를 방지하기 위해서 VisiPics 프로그램을 이용하여 데이터셋의 중복된 이미지가 있는지 확인 과정을 거쳤다.
VisiPics
VisiPics: Free software download for windows.
www.fosshub.com
해당 프로그램을 다운받은 후 수집한 이미지 데이터들 중 중복된 이미지가 있는지 확인하였다.
중복 검사를 원하는 폴더를 불러온 후에 오른쪽 Filter 부분의 단계를 슬라이더로 원하는 만큼 조절하면 된다.
Loose, Basic, Strict로 단계가 표시 되어 있으며 Strict로 갈수록 조금이라도 유사하면 중복으로 체크된다.

중복 체크가 끝나면 아래 사진처럼 왼쪽에 유사한 이미지들이 나열된다.
해당 이미지들을 확인한 후 같은 이미지일 경우, 한 장만 남기고 중복된 이미지들은 제거해주었다.

visipics 중복 체크
다음으로 객체를 인식하기에 적절하지 않은 아래와 같은 이미지들을 삭제하였다.
아래의 사진들의 경우 장롱이라기엔 부적절한 이미지이다.

데이터셋을 모두 정리한 결과, 최종적으로train data :1903장 (wardrobe: 948장, notwardrobe: 955장)
test data : 653장의 데이터셋이 구축되었다.
[keras를 활용한 CNN 모델 학습]
이렇게 다시 정리한 데이터셋을 가지고 다시한번 CNN 모델을 학습해보았다.
약 2000장의 훈련데이터로 이전보다 데이터가 더 많아졌지만 모델 학습하기엔 적은 데이터라고 판단하여 이전과 같이 이미지 프로세싱을 거쳐 데이터를 확대하였다.
아래는 이미지를 회전, 블러, 사이즈 정규화 처리하는 함수이다.
위의 이미지 프로세싱 함수들을 사용하여 이미지 사이즈는 32로 설정하고 회전, 블러 처리 등을 거쳐서 데이터를 각 클래스마다 20000장으로 확대시켰다. 그 결과, 총 40000만장의 훈련 데이터셋을 구성하였다.
CNN 모델 구조
이미지 프로세싱을 위와 같은 CNN 모델 구조로 모델을 구축한 후 batch size는 32, epochs는 100으로 설정하고 학습을 진행하였다.약 2시간 반동안 학습이 진행되었고 모델의 정확도는 83%로 이전에 더 적은 이미지로 학습한 모델의 정확도 97%보다 더 떨어졌다.
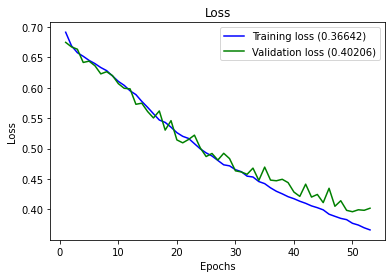
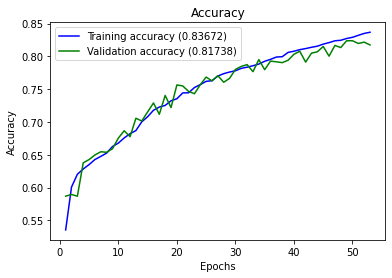
CNN 모델 학습 결과
테스트 데이터로 모델 평가를 진행하였는데 이것도 역시 76%의 정확도로 이전보다 더 낮은 수치이다.
CNN 모델 테스트 결과
이전에 웹크롤링한 이미지들로만 학습을 진행하였을 때는, 정확도는 약 87%가 나왔다. 이미지 데이터가 더 많아지면 정확도가 올라갈 것이라는 생각으로 이미지넷에서 더 많은 데이터를 수집한 것인데 예상과는 달리 모델 정확도가 약 76%로 현저히 떨어졌다.
위와 같이 정확도가 떨어진 이유를 생각해보았다. CNN은 이미지에서 객체의 부분만이 아닌 이미지 전체를 학습한다. 이전에 웹크롤링을 통해서 얻은 이미지들의 경우, 주로 전시된 이미지들이 많았다.
웹크롤링을 통해 얻은 장롱 이미지
위의 사진과 같이 이미지의 대부분은 장롱이 차지하고 있고 해당 객체의 주변부는 별 다른 물체가 존재하지 않는 경우가 많다. 그래서 이미지의 전체를 학습해도 정확도가 많이 떨어지지는 않았던 것 같다.
그러나 이미지넷을 통해 얻은 이미지들은 그렇지 않은 경우도 많았다.

이미지넷의 데이터 위의 사진들처럼 주변부에 다른 물체들이 있는 경우도 있고, 분류해야 할 객체가 이미지 구석에 작게 차지하는 경우도 있다.
따라서 이미지의 전체가 아닌 분류할 객체만을 인식할 필요를 느꼈고, CNN 모델이 아닌 객체 탐지를 통해서 이미지 속의 객체가 무엇인지를 파악하는 모델을 만들어야한다는 것을 알았다.따라서 객체탐지(object detection) 모델을 만들어 학습하기로 결정하였다.
[이미지 라벨링(labelImg)]
이번에는 CNN 모델이 아닌 YOLO를 활용한 객체 탐지(object detection)을 진행하려고 한다.
객체탐지(object detection)은 이미지나 동영상에서 사람, 동물, 차량 등 의미 있는 객체(object)의 종류와 그 위치(bounding box)를 정확하게 찾기 위한 컴퓨터 비전 기술이다.
따라서 객체 탐지를 진행하려면 사물의 이미지와 사물이 존재하는 위치 정보가 필요하다.- 이미지 라벨링 툴 설치(labelImg)
모델을 만들기 이전에 모델 학습에 필요한 이미지 데이터들을 라벨링하는 과정을 거쳐야한다.
여기서 라벨링이란 이미지에서 인식할 객체가 있는 부분에 사각형의 박스를 표시해서 객체의 위치를 표시해주고 해당 객체의 클래스를 지정하는 것이다.
객체의 위치를 표시한 사각형을 bounding box라고 하는데 bounding box와 클래스 정보가 xml이나 txt 형식의 파일에 담겨 해당 파일이 이미지 당 하나씩 생성된다.
이렇게 라벨링 작업을 하기 위해서 라벨링 툴인 labelImg를 사용하였다.
아래는 labelImg 툴의 깃헙 레포지토리이다.tzutalin/labelImg
🖍️ LabelImg is a graphical image annotation tool and label object bounding boxes in images - tzutalin/labelImg
github.com
labelImg를 사용하기 위해서는 필요한 설치 파일들을 먼저 다운로드 받아야 한다.
1. 위의 labelImg 링크에서 파일을 다운로드.
위의 labelImg 깃헙 링크에서 파일을 다운로드 받았다.
2. PyQt4, SIP 다운로드Riverbank Computing | Download
PyQt6 PyQt5 SIP PyQt-builder pyqtdeploy QScintilla PyQt4
www.riverbankcomputing.com

pyqt4 다운로드 페이지 위의 사이트를 들어가면 PyQt6, PyQt5, PyQt4가 있는데 그 중 PyQt4_gpl_win-4.12.3zip을 다운받는다.
mac 사용자의 경우 위의 파일을 다운받으면 된다.

SIP 다운로드 페이지 오른쪽 다운로드 목록에서 SIP를 선택해서 들어가면 SIP v4를 다운로드 할 수 있는 화면이 나온다. 여기서 sip-4.19.25.zip을 다운받았다.
3. lxml 다운로드Python Extension Packages for Windows - Christoph Gohlke
by Christoph Gohlke, Laboratory for Fluorescence Dynamics, University of California, Irvine. Updated on 17 May 2021 at 00:16 UTC. This page provides 32- and 64-bit Windows binaries of many scientific open-source extension packages for the official CPython
www.lfd.uci.edu

위의 페이지에 들어가면 여러 패키지들이 존재하는데 Lxml 부분에서 파이썬 버전에 따라 원하는 라이브러리를 다운받으면 된다. 필자는 lxml-4.6.3-cp37-cp37m-win_amd64.whl를 다운받았다.
위의 파일들은 모두 labelImg 툴을 실행시키기 위해 설치해야할 파일들이다.
이렇게 다운받은 파일들을 한 폴더에 저장한다.
4. anaconda prompt 실행
필자는 아나콘다 프롬프트를 사용하여 가상환경을 만들어 라벨링 툴을 실행시켰다. 다른 가상환경 플랫폼을 이용해도 무방하다. 아나콘다 프롬프트에서 labelImg-env라는 가상환경을 생성하였다.
labelImg-env를 생성한 후 가상환경을 실행시켰다. 그리고 labelImg가 있는 폴더, labelImg-master로 이동하였다.
labelImg-master 폴더로 이동하였으면 아까 다운받은 pyqt를 설치하면 된다.

pyqt가 설치된 후,
pyrrc5 -o libs/resources.py resources.qrc
python labelImg.py
위의 코드를 입력하면 labelImg가 실행된다.
labelImg 툴이 실행되면 아래와 같은 프로그램이 시작된다.
여기까지 진행되었다면 labelImg 설치와 실행은 모두 완료가 된다.- 이미지 라벨링 작업
이제 labelImg 툴을 사용해서 훈련 데이터들을 라벨링할 차례이다.
YOLO를 사용할 예정이므로 파일 형식은 TXT형식의 파일로 생성하려한다.
좌측의 메뉴에서 YOLO를 선택한 후 라벨링 작업을 시작한다.xml 파일을 원하면 PascalVOC를 선택하면 된다. 그러면 annotation 파일이 xml 파일로 생성된다.

yolo 형식으로 설정 우선 라벨링할 이미지를 툴로 불러온 다음, 객체가 위치한 부분을 bounding box 처리를 하였다.
(아래 사각형이 bounding box이다.)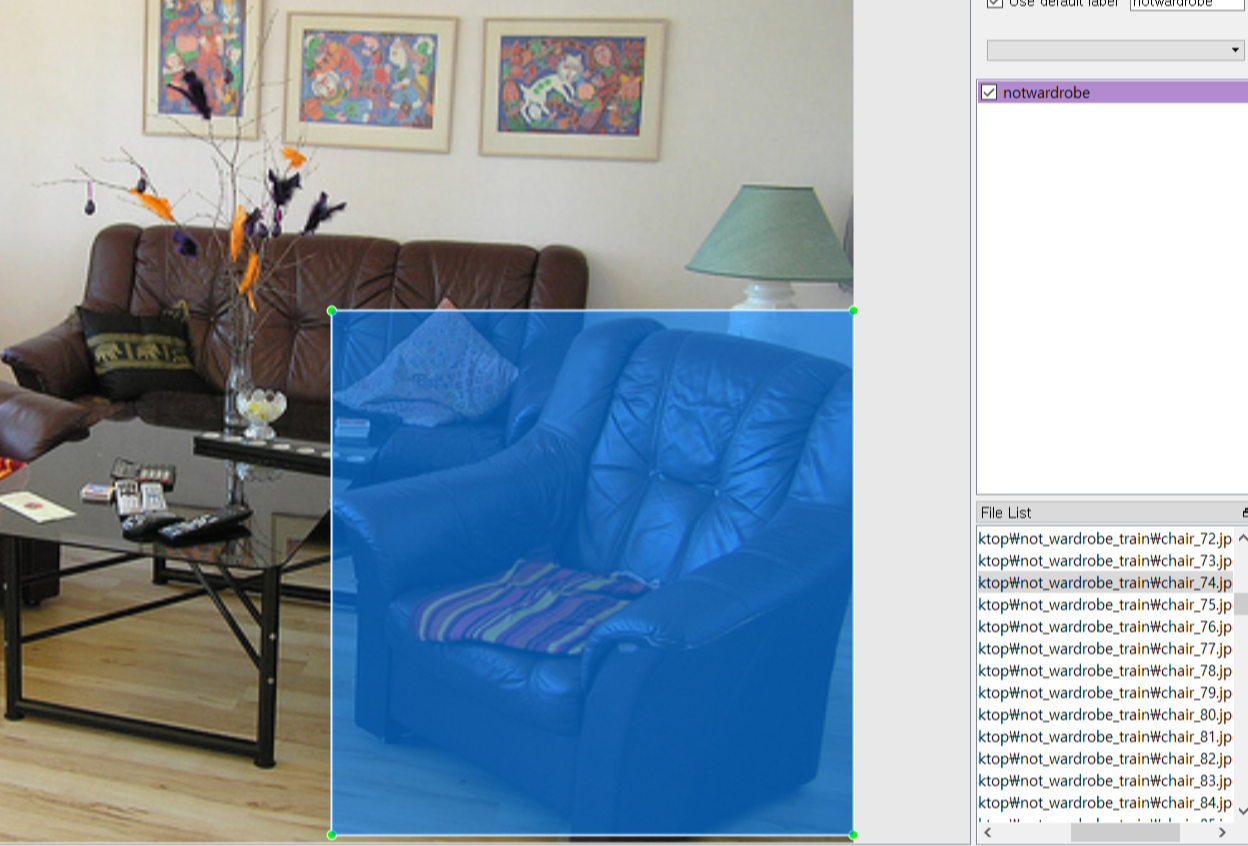
위의 이미지 속 객체는 소파로 해당 객체가 위치하는 부분을 사각형으로 표시해 준 다음 클래스를 notwardrobe로 지정해주었다.
(객체가 장롱일 경우 wardrobe로 지정해주면 된다.)
이렇게 라벨링을 마치면 notwardrobe는 클래스 1(wardrobe는 클래스 0)로 지정되고, bounding box의 가운데 지점의 좌표와 높이와 너비가 txt파일로 생성된다.
notwardrobe txt 파일 
wardrobe txt 파일
이렇게 훈련데이터 1903장의 라벨링을 마치고 이미지 정보를 담은 txt파일을 1903개 생성하였다.
위 과정을 마치면서 yolo 모델 학습을 위한 모든 준비는 완료된다.
[Object Detection : YOLOv4-tiny 모델 학습]
해당 서비스를 제공하는 매체가 모바일 어플리케이션이므로 모바일에 올리기 적합한 yolov4-tiny 모델로 학습하였다.
yolo 모델은 구글에서 제공하는 가상환경 플랫폼인 colab을 사용하여 학습하였다. colab에서는 gpu 환경을 제공하기 때문에 cpu에서 모델을 학습시키는 것보다 모델 학습 시간을 단축시킬 수 있다.
모델 학습을 위한 전체 과정은 이렇다.
1. colab 런타임 환경 설정
2. 구글 드라이브 파일 업로드 후 연결
3. darknet git repository 가져오기
4. makefile 설정
5. darknet directory 설정 및 데이터 스크립트 생성
6. yolov4-tiny weights 다운로드
7. training
위의 단계를 따라서 모델 학습을 진행하였다.
1. colab 런타임 환경 설정
빠른 모델 학습을 위해서 하드웨어 가속기를 GPU로 설정해주었다.
GPU 설정으로 좀 더 빠른 모델 학습이 가능해진다.
2. 구글 드라이브 파일 업로드 후 연결
모델을 학습시키기 전에 구글 드라이브에 훈련데이터(obj.zip), process.py, 클래스명이 적힌 obj.names 파일, obj.data 파일들을 업로드 해야한다.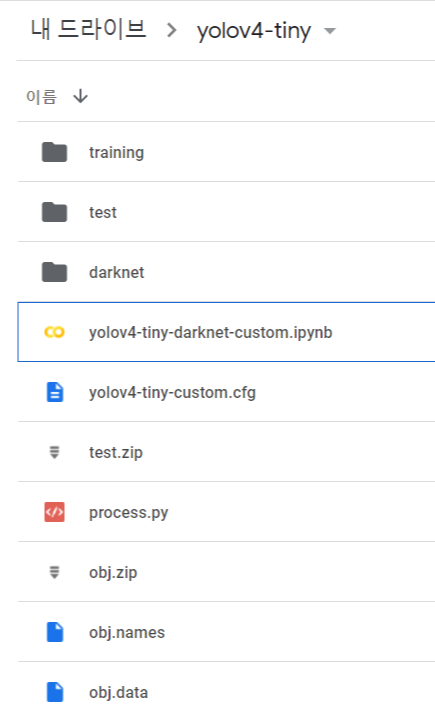
여기서 obj.names에는 아래와 같이 클래스명을 입력해야한다.
obj.data에는 아래와 같이 클래스 수, train, valid 데이터 위치, obj.names 위치, backup 위치의 정보를 적어서 업로드하였다.

training 폴더는 학습된 모델의 weights를 저장하기 위한 폴더로 빈 폴더로 생성해주면 된다.
이렇게 드라이브에 필요한 파일과 폴더를 업로드 하였고 다시 colob notebook으로 돌아가서 구글 드라이브와 연결을 해주었다.
구글 드라이브를 마운트한 다음 현재 위치를 yolov4-tiny로 이동해서 폴더 내 파일들을 확인하면 업로드 한 파일들이 존재하는 것을 확인할 수 있다.
3. darknet git repository 가져오기
AlexeyAB의 darknet 레포지토리를 clone하여 코랩 환경으로 가져오는 작업이다.
이렇게 colab에 복제하면 코랩 환경 내에서 darknet을 사용할 수 있다.
4. makefile 설정
darknet 폴더로 이동한 후, OPENCV와 GPU를 사용할 수 있도록 makefile을 수정하는 과정이다.- GPU=1 GPU를 사용하여 가속하는 CUDA를 사용하여 빌드
- CUDNN=1 GPU를 사용하여 training을 가속화하기 위해 cuDNN v5-v7로 빌드
- CUDNN_HALF=1 Detection은 3배, training은 2배 빠르게 하기 위해 Tensor Cores 빌드(on Titan V / Tesla V100 / DGX-2 and later)
- OPENCV=1 OpenCV 3.x/2.4.x로 빌드 - 네트워크 카메라 또는 웹 캠의 비디오 파일 및 비디오 스트림 탐지하게 해줌
- LIBSO=1 darknet.so 라이브러리를 빌드, 이 라이브러리를 사용하는 이진 실행 파일 usedlib를 사용
위의 내용들은 깃헙 레포지토리에서 확인할 수 있으며 readme를 보고 런타임에 필요한 설정들을 해주면 된다.

OPENCV, GPU뿐만 아니라 CUDNN, CUDNN_HALF, LIBSO도 사용 가능하도록 1로 설정해주고 셀을 실행시켰다.
makefile을 수정한 후 darknet를 빌드해준다.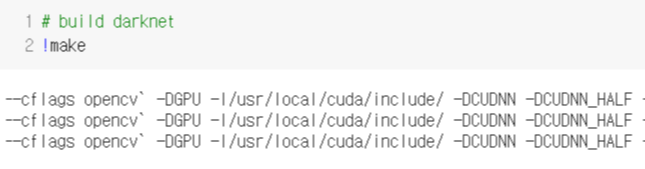
5. darknet directory 설정 및 데이터 스크립트 생성
이전에 드라이브 yolov4-tiny에 올린 파일들을 darknet에서 사용할 수 있도록 darknet의 디렉토리에 복사하는 과정이다.
필요한 데이터의 label 폴더를 제외하고 먼제 data와 cfg 폴더를 빈 파일로 만들어주었다.
yolov4-tiny에 업로드한 wardrobe, notwardrobe 이미지, txt 파일들을 darknet/data 폴더로 복사하였다.
cfg, obj.names, obj.data 파일들도 앞에 훈련데이터 파일들과 같이 darknet/data 폴더에 복사하였다.
data 폴더에 train.txt와 test.txt 파일을 생성하기 위해서 process.py을 실행시켰다.
process.py 파일은 train.txt와 test.txt에 각각 train과 valid에 사용되는 데이터들의 파일명을 담아준다.
ls data/ 코드를 통해 data 폴더 안에 모델 훈련을 위한 파일들이 darknet에 생성되었음을 확인하면 된다.
6. yolov4-tiny weights 다운로드
모델학습에 사용할 pretrained weights, yolov4-tiny.conv.29 가중치 파일을 다운받았다.
학습할 모델에 맞는 가중치 파일을 다운로드 해야한다.
가중치 파일들은 AlexeyAB의 다크넷 레퍼지토리에서 확인하고 원하는 가중치 파일을 다운로드하면 된다.

7. training
6번까지 필요한 설정들과 파일들은 모두 준비가 된 것이다. 이제 모델 학습의 과정이다. 다운받은 pretrained weights yolov4-tiny.conv.29를 가지고 훈련 데이터들을 학습시켰다.
학습이 모두 끝나고 mAP를 계산해보았다.
wardrobe 클래스에 대한 정확도는 86.96%, notwardrobe 클래스에 대한 정확도는 79.06%가 나왔고,
전체 mAP는 약 83%가 나왔다.
모델 학습에서 나온 weights 파일들은 드라이브에 생성한 training 폴더에 저장되었다.
이곳에 저장된 가중치 파일들을 사용해서 detection을 진행하면 된다.
아래 그래프는 학습이 진행 횟수에 따른 정확도 그래프이다. batch size를 6000으로 잡았는데 약 5200에서 정확도가 83%로 향상되고 학습이 끝날 때까지 정확도가 개선되지 않았다.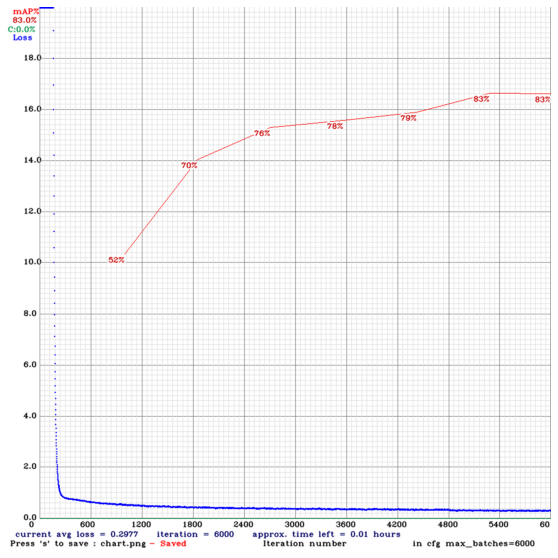
이번 yolo 학습에서는 이전 CNN 모델처럼 데이터를 확대하지 않은 채 훈련 데이터 1903장만을 가지고 학습을 시켰다.
아무래도 모델 학습에 사용된 데이터의 양이 적기 때문에 정확도가 높게 나오지 않은 듯하다. 이번 학습으로 데이터 확대 과정은 필수적이라고 판단하였다.
원래 계획은 모바일 앱에 모델을 올려서 detection을 하는 것이었다. 그래서 모바일에 적합한 yolov4-tiny를 학습했는데 해당 모델을 tflite 파일로 변경하여 모바일에 올리면 detection의 정확도가 다소 떨어지며, 앱 자체가 무거워진다는 것을 다른 모델로 테스트를 하면서 깨달았다.
따라서 기존의 계획을 수정하여 yolov4-tiny 보다 조금 더 성능이 좋은 yolov4 모델을 사용해서 객체 탐지를 진행하기로 결정하였다. yolov4로 학습한 weights 파일을 서버에 올려서 서버와 안드로이드 앱이 통신을 하여 이미지와 detection의 결과값을 주고 받는 시스템으로 진행하기로 계획을 수정하였다.[image augmentation]
YOLOv4-tiny 모델 학습에서 데이터 확대의 필요성을 느꼈다.
따라서 이미지 프로세싱(이미지 회전)을 통한 데이터 확대를 진행하였다.
이번 작업은 anaconda jupyter notebook를 통해서 진행하였다.
Jupyter Notebook을 실행시킨 후, image augmentation 이라는 py파일을 생성하여 작업을 진행하였다.
image augmentation은 이미지뿐만 아니라 bounding box의 위치도 함께 수정되어 이미지 프로세싱이 된 새로운 이미지에 대한 txt 파일이 생성되어야 한다.
따라서 yolo format의 정보를 opencv format으로 변환하는 과정이 필요하다.
아래 이미지는 해당 과정을 수행해주는 yoloFormattocv 함수이다.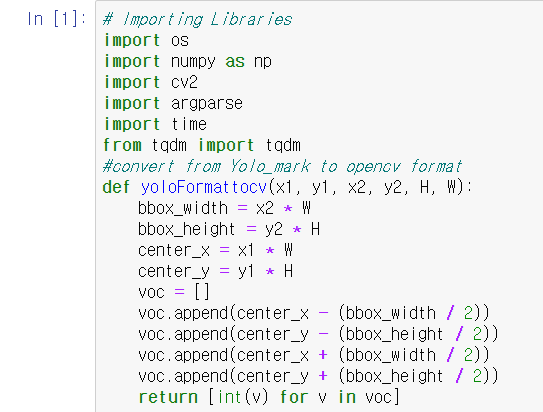
yolo에서는 bounding box의 너비, 높이, 가운데 좌표의 정보가 나와있는데, 이 함수는 해당 수치들을 다시 계산해서 bounding box의 각 꼭지점의 좌표를 반환해준다.
opencv의 format을 다시 yolo format으로 변환하는 과정 또한 필요하다.
아래 이미지는 해당 과정을 수행해주는 cvFormattoYolo 함수이다.
이 함수는 bounding box의 각 꼭지점의 좌표를 이용해서 box의 가운데 좌표와 box의 너비, 높이, bounding box의 가운데 좌표를 반환해주어 다시 yolo의 형태로 만들어준다.
format을 변환하는 함수를 작성한 후 훈련 데이터의 bounding box와 이미지를 원하는 각도만큼 회전시키는 함수를 만들어 이미지 프로세싱을 진행하였다.
yoloRotatebbox 클래스를 생성해서 이미지를 회전시키기 위한 코드를 작성하였다.우선, 프로세싱할 이미지를 opencv로 불러오고 해당 파일의 txt파일도 불러온다.
파일명, 프로세싱한 이미지 저장 디렉토리, 회전시킬 각도들은 array 형태로 파라미터로 받도록 하였다.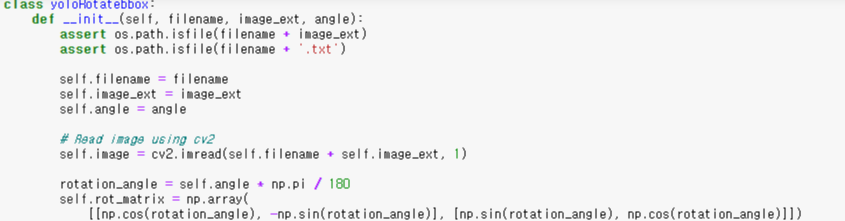
txt 파일을 열고 좌표들을 가져와 yoloFormattocv 함수를 사용해서 opencv 형태의 좌표들로 바꾸어주고, 회전시키고 난 후의 좌표값을 계산하여 새로운 bounding box를 반환하도록 하였다.
rotate_image는 이미지를 회전시키는 함수이다.
이미지의 높이랑 너비, 이미지의 가운데 좌표를 받아온 후, opencv의 getRotationMatrix2D 함수를 사용해서 지정한 각도만큼 이미지를 회전시킨다.
회전시켜서 얻은 좌표로 sin값, cos값을 구할 수 있으며 이 값들로 다시 회전시킨 이미지의 높이와 너비를 구할 수 있다.
클래스 함수의 정의를 다 하였고 해당 함수들을 이용해서 이미지 프로세싱을 진행하였다.
먼저 각도를 45, 90, 135, 180, 225, 270, 315로 설정해서 각 이미지별로 7개의 데이터를 더 만들었다.
각 각도마다 rotateYolobbox와 rotate_image를 사용해서 이미지를 수정하고 새로운 좌표값을 생성하였고, cvFormattoYolo 함수를 사용하여 YOLO 형태의 txt 파일을 생성해주었다.
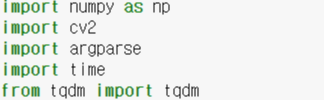
맨 아래 progress bar는 진행률을 나타내주는 것으로 아래 tqdm 라이브러리를 추가하면 된다.
이미지 프로세싱이 모두 수행되고 회전된 이미지들이 저장된 폴더에서 목록을 보면 파일명에 '_각도' 의 형태로 파일들이 저장되어 있는 것을 확인할 수 있다.
프로세싱된 파일들을 열어서 확인해보았다.
아래는 90도로 회전된 이미지 파일과 텍스트 파일이다.

다음은 135도로 회전된 이미지와 텍스트 파일이다.

결과물을 보면 각도에 맞게 회전되었고 각 각도마다 다르게 txt 파일의 수치가 수정되었음을 확인할 수 있다.[Object Detection : YOLOv4 모델 학습]
이렇게 확대시킨 데이터셋을 가지고 다시한번 모델을 학습시켜 보았다.
이전에 yolov4-tiny 모델을 학습한 과정과 똑같으며, 데이터 셋과(data/obj) pretrained weights 파일만 변경되었다.
아래와 같이 여러 각도들로 회전된 이미지 데이터들을 darknet의 data 폴더에 저장하였다.
pretrained weights를 yolo4.conv.137로 다운받은 후 해당 가중치로 모델 학습을 진행하였다.
pretrained weights 다운 
모델 학습 실행 화면
데이터가 이전보다 8배 많아진 관계로 학습을 진행하는데 이전보다 훨씬 오랜 시간이 걸렸다.
약 10시간 동안 모델 학습을 진행하였고 모델 학습 결과 약 98%의 정확도가 나왔다.
이전에 YOLOv4-tiny 모델로 학습시켰을 때 83% 정확도가 나왔는데 그 때보다 훨씬 정확도가 높아졌다. 모바일 전용인 tiny 모델에서 YOLOv4 모델로 변경하여 학습을 진행하였기 때문에 모델로 인해 정확도가 약간 높아졌을 수도 있지만 이렇게 큰 차이가 나는 것은 데이터 확대가 큰 역할을 하였다고 생각한다.모델 학습 결과로 나온 yolov4-custom_best.weights 가중치 파일을 이용해서 실제 테스트 데이터로 모델 테스트를 진행해보았다.
테스트 이전에 모델 학습 이전에 업로드 하였던 yolov4-custom.cfg 테스트에 맞게 수정해야한다.
batch size는 64로 설정하였던 것을 1로, subdivisions를 16을 설정하였던 것 또한 1로 수정한다.

dectection에 yolov4-custom_best.weights를 지정해주고, 테스트할 이미지 파일을 써준다.
그리고 마지막에 -thresh 0.4로 지정해주었다.
여기서 thresh는 해당 객체일 확률을 의미하는 것으로 인식한 객체가 맞을 확률이 40%이상일 경우에만 결과를 출력하도록 하는 것이다.
import os from google.colab.patches import cv2_imshow !./darknet detector test data/obj.data cfg/yolov4-custom.cfg /mydrive/yolov4/training/yolov4-custom_best.weights /content/gdrive/MyDrive/yolov4/test/test2/wardrobe2202_jpg.rf.2c4abec8691f3c083333dc3c25453173.jpg -thresh 0.4총 테스트 이미지 653장를 테스트한 결과, 객체 탐지는 모델 정확도보다는 좀 낮게 나왔다. 약 96%의 객체탐지 정확도가 나왔다.
아래 이미지들은 테스트데이터를 가지고 모델에 적용해 본 예시들이다.
아래 장롱을 테스트한 결과, wardrobe : 100%의 결과가 나온다.


다른 이미지들도 테스트 해보면, wardrobe : 99%로 장롱이 잘 인식됨을 확인할 수 있다.


이번엔 장롱이 아닌 이미지를 테스트해보았다. 식탁 이미지로 notwardrobe 클래스에 해당되는데 약 98%로 학습된 모델로 잘 인식되었음을 확인할 수 있었다.


이렇게 이미지 프로세싱을 통한 이미지 데이터 확대 과정을 거치고 YOLOv4 모델을 학습시켜서 장롱 객체를 인식하는 탐지 모델을 만들었다. 해당 모델은 서버에 올린 후 모바일 어플리케이션에서 이미지를 보내면, 그 결과값을 주고 받는 형식으로 통신하였다. 그렇게 대형 폐기물 배출 서비스 프로젝트에서 품목 인식 부분을 객체 탐지 기술을 활용하여 서비스를 제공하였는데 아래는 프로젝트 결과물로 모바일 어플리케이션을 통해서 품목 인식이 되는 화면이다.

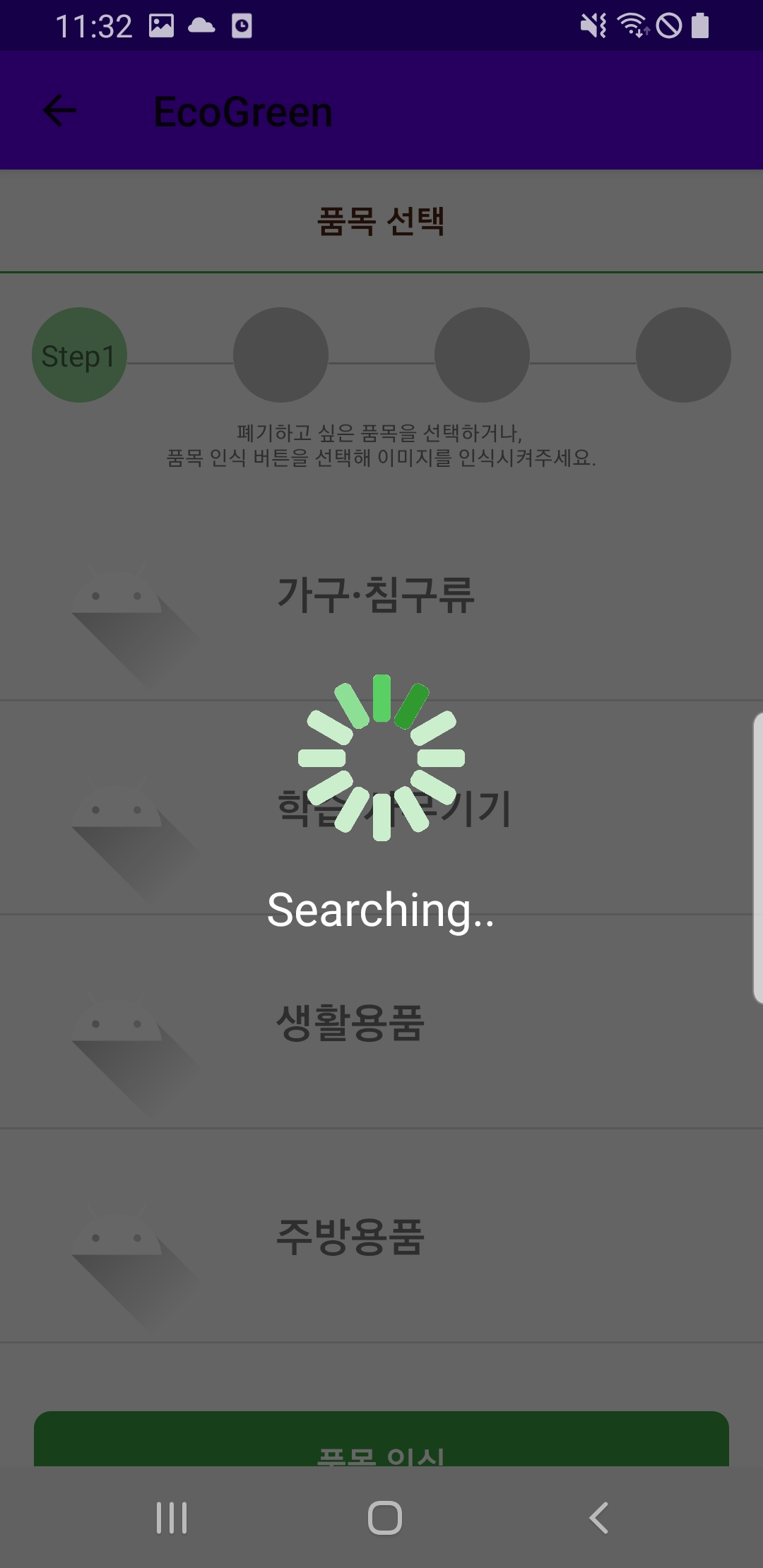
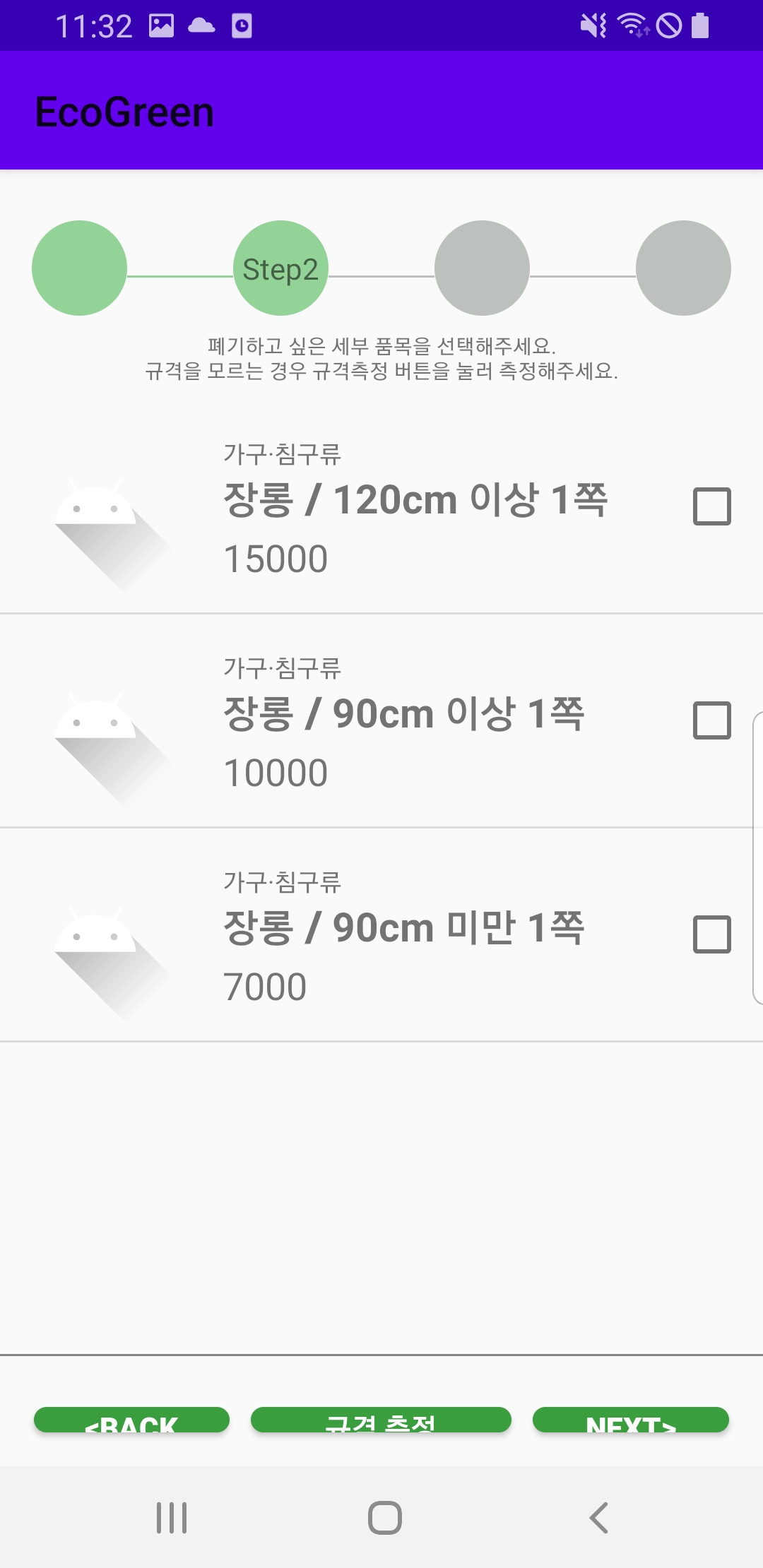
가장 왼쪽 화면의 25_jpg 파일을 선택하여 객체 탐지를 진행한다. 객체 탐지가 진행되는 동안 searching 이라는 문구가 뜨고, 이후 장롱이라고 객체가 인식되면 가장 오른쪽 화면과 같이 장롱 품목의 규격 목록이 제공되는 것으로 보아 객체 인식이 잘 되었음을 확인할 수 있다.
서버를 구축하고 모델을 올리는 작업은 다른 포스팅에서 설명하도록 하고 장롱 이미지 인식해주는 딥러닝 관련 포스팅은 여기서 마치겠다!!
'Develop > 졸업프로젝트' 카테고리의 다른 글
[딥러닝] 케라스(Keras) CNN을 활용한 장롱 이미지 분류하기 (0) 2020.11.27 [딥러닝] 합성곱 신경망(Convolutional Neural Network, CNN) (0) 2020.11.27 [딥러닝] 이미지 데이터 전처리 (0) 2020.11.26 [web crawling] 파이썬 selenium 이미지 크롤링 (0) 2020.11.25 댓글
